关于创建mysql连接池的具体思路和实现

关于创建mysql连接池的具体思路和实现
幻雪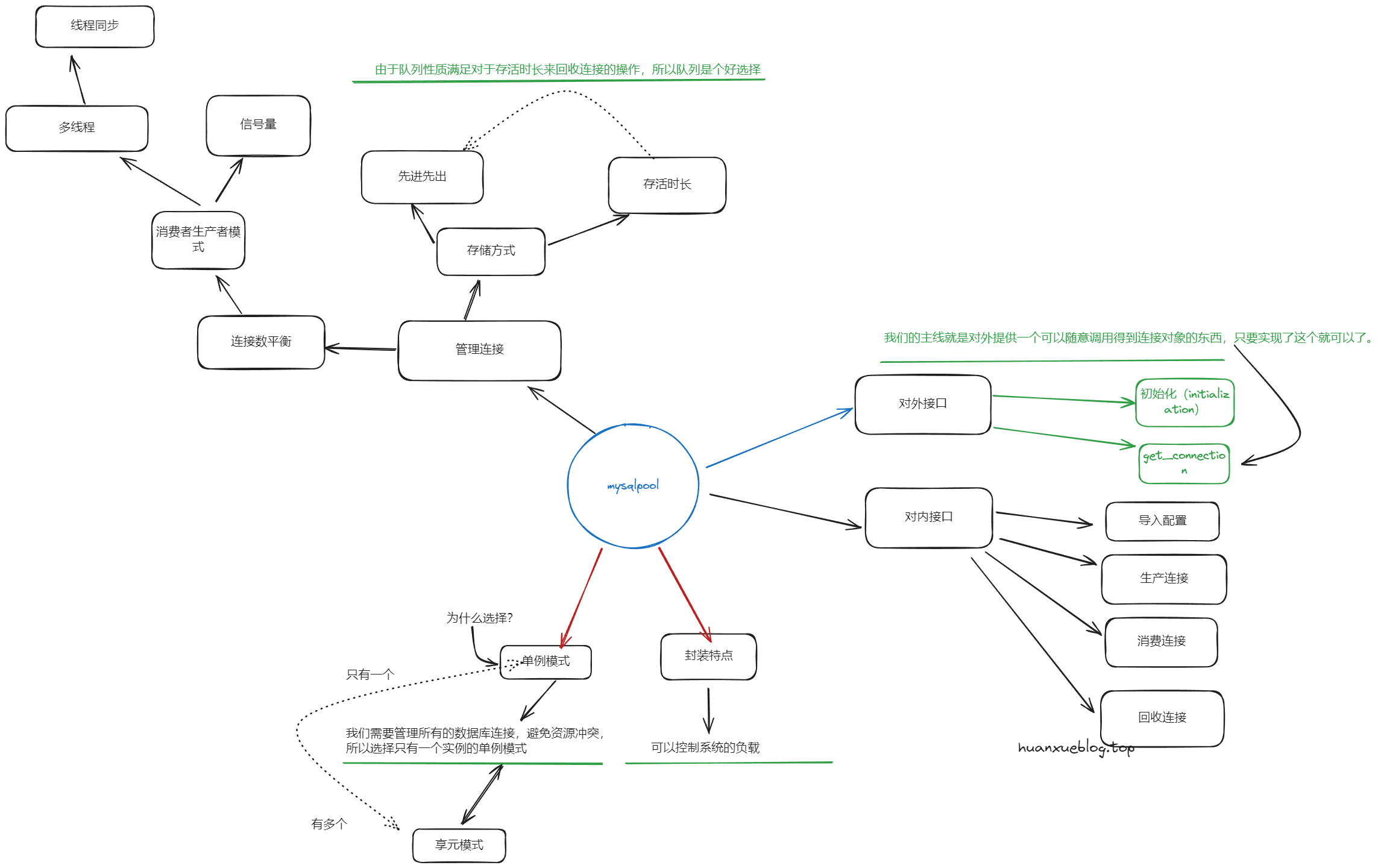
单例设计思路
单例推荐采用的是 c++11 支持的性质:”在 C++中,函数内部可以声明静态局部变量。这些变量在函数第一次执行到它们的声明时进行初始化,并且在程序的整个运行期间保持它们的值,即使函数已经返回。每次函数被调用时,这些变量都会保持它们上一次调用结束时的状态。”
也就是说,只要被执行一次,那么就会初始化,且只初始化一次。
所以也引出我们单例设计的模式:“magic static“
其他的单例模式不是很推荐,因为或多或少都有其他的问题,像 饿汉模式,如果程序运行过程中可能不会使用到该单例,会导致资源浪费,而 双重检查锁定模式 会因为编译器的优化导致出现线程安全问题,就是你想的和编译器以为的不一样。还有就是 枚举类型 实现起来繁琐且不直观。
所以采用 magic static 的方式,简单且安全
1 | // 获取单例实例 |
RAII 设计思路
我们获取当前的连接池的单例后,要考虑的就是如何写我们的构造函数,这个应该参照 RAII 设计
RAII 模式,也就是“资源获取即初始化”,为的是将资源的获取和释放与对象的生命周期绑定在一起。当对象被创建时,它负责获取所需的资源;当对象被销毁时,它负责释放资源。
所以我们的构造函数和析构函数就要围绕构造的时候获取什么?析构的时候顺带销毁什么?
连接池,那就是 sql 连接管理的池子,自然就是构造函数获取初始连接,析构函数析构所有连接
所以设计上应该需要在构造函数和析构函数中设置两个循环,分别管理连接
1 | ConnectionPool::~ConnectionPool() |
生产者线程,消费者线程
- 首先生产者线程应该有生产函数
- 消费者线程有消费函数
- 两者线程应该分离开来区别于主线程
所以引出三个问题
主线程是什么?
消费者函数怎么写?
生产者函数怎么写?
主线程
母庸质疑就是调用线程池的 main 方法。
那么不可能在调用 main 方法的地方我们分离生产者函数和消费者函数,因为我们是封装好的类,应该只提供让用户 get 的接口,而不是让用户操作,应该让用户将其看成黑盒,而不是做更多的操作。
所以,应该如何分离消费者线程和和生产者线程呢?
首先,从线程安全的角度看,如果生产者,消费者线程,启动得太快,那么就会访问到未初始化的数据,如果启动得太慢,又无法动态调整连接数量,导致响应过慢,影响效率。
再从职责上讲,函数无非就是 getconnection ,produceConnection,recycleConnection getInstance
什么样的函数就应该只做怎么样的事情,所以选择在构造函数中分离生产函数和消费函数。
1 | ConnectionPool::ConnectionPool() |
生产者函数
生产函数 produceConnection
首先他需要线程分离,然后 不断 地去判断一些条件,符合条件的就生产,因为 不断 所以我们必须用 while 来覆盖住整个函数。
前面提到,如果我们需要按时间回收,用队列是比较好的选择,所以我们存储方式是选择队列,当符合条件就生产,加入队列。
那么这个条件是什么呢?
这个条件有两点
- 第一如果队列中有可用连接就不生产
- 第二如果生产连接达到上限就不生产
这样做就可以让连接维持在一个规定的上界,同时让队列始终保持有连接。
随后当我们调用完函数以后就需要通知消费者消费,所以函数最后要加一个信号量通知。
但有一个问题,生产者如果不生产需不需要通知消费者?
事实上是不需要的,等待调用连接结束,可以通过智能指针回收连接到队列当中,同时再唤醒消费者即可。
所以整个的逻辑是
当消费者消费时,生产者就得被唤醒,判断队列是否为空,如果为空,就说明需要生产连接,再判断是否生产在上限以内,如果是就生产,然后唤醒,不是就重新循环等待被唤醒。
1 | void ConnectionPool::produceConnection() |
消费者线程
getconnection
消费者线程就是 getConnection 函数和recycleConnection函数两个函数,我们先说 getConnection,getConnection 是主线程用户调用的线程,通过调用获得连接。
getConnection无非就是拿的过程,从什么地方拿?从队列中拿,拿取头一个元素,返回的是一个指针类型。
那么拿走的连接如何还回到队列当中呢?时间上肯定是需要单用户结束调用的时候,还回到队列当中,一般的想法是提供一个用户接口,让用户把连接放进去,但是这样太不优雅了,不应该让用户管理释放。
那么回到刚刚说的,返回的是一个指针类型,是不是就可以考虑智能指针,来管理连接。通过lambda函数,把释放的链接放入队列。另外的关于智能指针的选择,推荐使用独占智能制造,因为共享智能指针可能会被用户错误的使用导致循环引用等问题,同时出现bug也不好寻找析构的代码行。所以优先考虑独占智能指针。
那么回到代码上来,首先getConnection函数是通过用户主线程调用的,所以是不需要向分离线程一样,使用一个while来维持线程运作,这是区别于生产者线程和回收者线程的。
首先通过锁实现线程同步,再去访问当前的队列有没有连接,有连接就拿。没有连接就阻塞一段时间,再访问,如果没有得到打印错误信息,直接返回空。得到的连接用智能指针管理,释放智能指针的时候,同时把连接放回队列当中。最后通知生产者判断有没有必要生产,返回一个智能指针类型。
1 | shared_ptr<MySqlConn>ConnectionPool::getConnection() |
回收线程
回收线程的设计是基于如果多余的连接超时就释放连接,以保证空闲时没有大量的连接占用。
因为需要再后台去轮询所有的连接是否超时,所以需要用到线程分离,那么就需要一个while循环这个函数代码。
但是也不能一直轮询,会浪费cpu调度,那么就使用一个sleep隔一段时间回收一次。
回收的时候需要对队列资源进行访问,所以要用到锁,上一个锁然后开始访问资源,访问哪一个资源呢?如果回收连接的话,回收那一刻一定是最新的,所以在队头的一定是最旧的,所以从队头到队尾轮询时间。
如果此时连接数量大于初始设置数量,且超时,那么就回收连接,否则就直接返回,因为如果当前没有超市,后面更新的也不会超时了。
1 | void ConnectionPool::recycleConnection() |
一些额外的问题
如果我们考虑使用一个close函数通过while配合信号量,当返回的时候通知close判断是否符合析构条件,如果析构,听起来好像还行,但是问题在于,我们的析构函数是不应该被成员函数调用的,如果成员函数使用了成员变量,那么这个成员变量被析构了又在成员函数作用域,这样容易引起错误。
所以我对此的想法就是做再做一个集合,存放分出去的连接,当析构函数被调用的时候,两个集合都便利一遍,释放就可以了。
所以在getConnection函数中我们把连接添加到分出去集合
在lambda中,我们从分发集合中删除该连接。
所以我们通过分发集合和空闲队列一起管理连接的建立。
这样就把在外的和在内的连接都回收了就不会出现连接回收的问题。
源码
.cpp
1 |
|
.h
1 |
|